Hello guys,
my company has been using this C# Library for years now but I’m rather new to it. Currently we have the requirement to generate a csv file in a rather unique format.
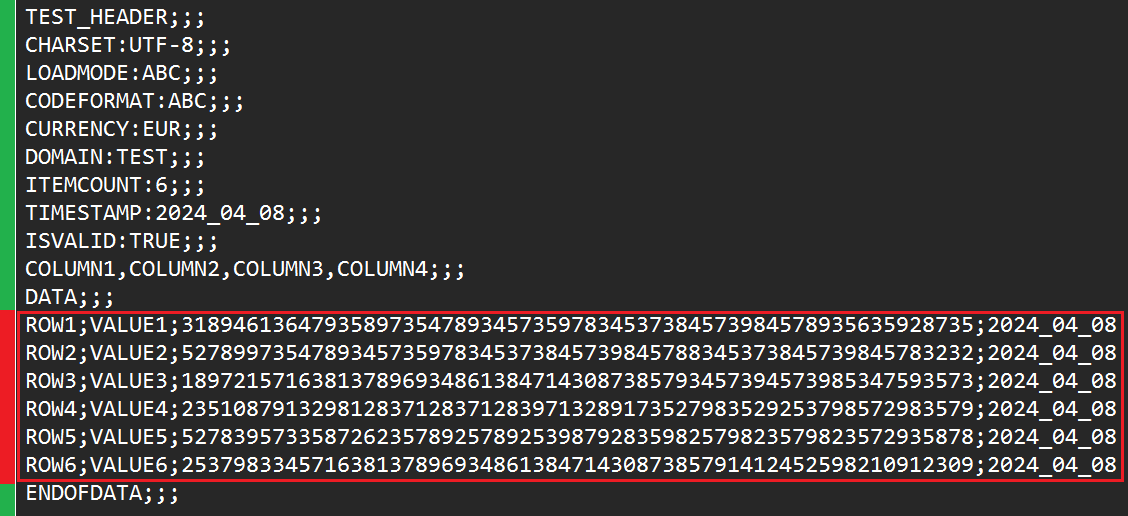
Here’s an example (simplified and with test data) of the current output:
We basically have two areas:
- The red area is normal csv content without any headers. It has 4 columns and 6 rows in this simplified example.
- The green area are (more or less) normal static values. But all the green rows have one thing in common: They only have one column.
Now for the issue:
The column count of the red area is also applied to the green area. I guess this is because the column count is defined by the framework globablly for the entire csv file? Can we somehow define the amount of columns depending on the “block” or “area” or for each row individually and dynamically? The green area must not own multiple columns/cells and therefore must not have these ; delimiters.
Thanks in advance!
An example Mockup should look like this:
TEST_HEADER
CHARSET:UTF-8
LOADMODE:ABC
CODEFORMAT:ABC
CURRENCY:EUR
DOMAIN:TEST
ITEMCOUNT:6
TIMESTAMP:2024_04_08
ISVALID:TRUE
COLUMN1,COLUMN2,COLUMN3,COLUMN4
DATA
ROW1;"VALUE1";"3189461364793589735478934573597834537384573984578935635928735";2024_04_08
ROW2;"VALUE2";"5278997354789345735978345373845739845788345373845739845783232";2024_04_08
ROW3;"VALUE3";"1897215716381378969348613847143087385793457394573985347593573";2024_04_08
ROW4;"VALUE4";"2351087913298128371283712839713289173527983529253798572983579";2024_04_08
ROW5;"VALUE5";"5278395733587262357892578925398792835982579823579823572935878";2024_04_08
ROW6;"VALUE6";"2537983345716381378969348613847143087385791412452598210912309";2024_04_08
ENDOFDATA
EDIT: I forgot to mention that I clicked through some pages in the documentation, but I didn’t find anything about our specific issue.
Yes, it is defined for the entire worksheet.
No, unfortunately, there is no such option.
However, you could achieve your requirement by moving the rows in those green areas into separate sheets and then saving all the sheets into the same CSV file.
For example, like this:
var workbook = ExcelFile.Load("input.xlsx");
var dataSheet = workbook.Worksheets.ActiveWorksheet;
var dataRows = dataSheet.Rows;
var headerSheet = workbook.Worksheets.InsertEmpty(0, "Header");
var headerRows = headerSheet.Rows;
int sourceRowIndex = 0;
int destinationRowIndex = 0;
// If a row has only one allocated cell, move it to a separate sheet.
while (dataRows[sourceRowIndex].AllocatedCells.Count == 1)
{
headerRows.InsertCopy(destinationRowIndex++, dataRows[sourceRowIndex]);
dataRows.Remove(sourceRowIndex);
}
// Remove the last empty row.
if (headerRows[headerRows.Count - 1].AllocatedCells.Count == 0)
headerRows.Remove(headerRows.Count - 1);
var footerSheet = workbook.Worksheets.Add(0, "Footer");
var footerRow = footerSheet.Rows;
sourceRowIndex = dataRows.First(r => r.AllocatedCells.Count == 1).Index;
destinationRowIndex = 0;
// If a row has only one allocated cell, move it to a separate sheet.
while (dataRows[sourceRowIndex].AllocatedCells.Count == 1)
{
footerRow.InsertCopy(destinationRowIndex++, dataRows[sourceRowIndex]);
dataRows.Remove(sourceRowIndex);
}
// Remove the last empty row.
if (footerRow[footerRow.Count - 1].AllocatedCells.Count == 0)
footerRow.Remove(footerRow.Count - 1);
// Save multiple sheets into a single CSV file.
var options = new CsvSaveOptions(CsvType.SemicolonDelimited);
using (var writer = File.CreateText("output.csv"))
foreach (var sheet in workbook.Worksheets)
{
workbook.Worksheets.ActiveWorksheet = sheet;
workbook.Save(writer, options);
}
I hope this helps.
Regards,
Mario
Hello,
thank you very much! I tested your suggestion and it worked!
I’m currently trying to make this code compatible with the old legacy code without breaking anything.
So I made three steps:
- Generate the file as xlsx and save it as originally as xlsx.
- After that, copy the original filepath variable (“…TestFile.xlsx”) into the actual required path (“…TestFile.csv”) and save it in a new string variable.
- Open the XLSX-File, execute your logic and save it as a csv.
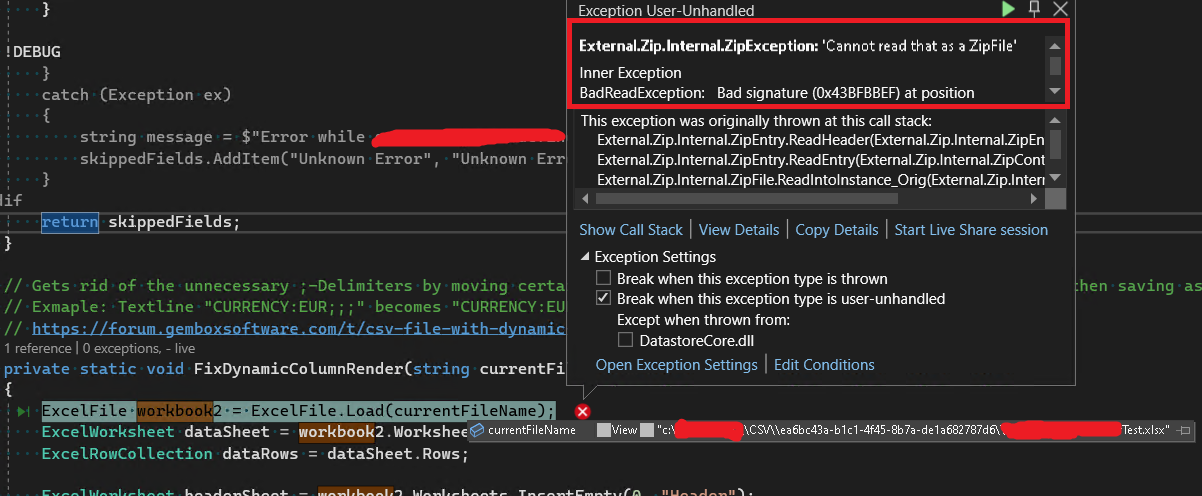
However, during reading/opening of the file in the third step, I get the following exception:
The ExcelFile.Load() method seems to want to read the xlsx-File as a zip, even though the xlsx-file is on a normal (non zipped) folder on the drive. I tried multiple overloads (for example also passing LoadOptions.XlsxDefault), but it doesn’t change the behavior.
I also tried to google, but couldn’t find a solution. Do you have an idea what could cause this behavior?
Edit: Okay nevermind, I found the reason: I was saving the file as a .xlsx but with CsvSaveOptions. Fixed it and now it works! Thank you very much!!